GTOの次なる進化:QRE(質的応答均衡)

2015年に最初の商用ポーカーソルバーが登場して以来、ナッシュ均衡(NE)は最適戦略の金字塔として君臨してきました。今回、私たちはその常識に一石を投じます。
今回紹介するQRE(質的応答均衡)は、最適戦略を導くためのまったく新しいアプローチです。従来のナッシュ均衡が「相手が完璧にプレイする」という仮定に基づいていたのに対し、QREではプレイヤーは現実にはミスを起こし得ることをすことを前提に、それに対する最適応答を計算します。さらに、GTO Wizard AIの継続的な改善によりフロップとターンの計算精度が25%向上し、これまで以上に高速かつ高精度で強力になりました。
この記事では、なぜQREが次世代の最適戦略と言えるのか、わかりやすく解説します。
本アップデートの影響範囲
本アップデートは、GTO Wizard AIを使用して解くカスタムソリューションにのみ適用され、ユーザーが解くすべてのカスタムスポットでは、QREアルゴリズムが使用されます。カスタムソリューションを利用する際は、エリートプランの契約が必要です。
※Q♠T♠7♥のフロップは無料でご利用いただけます。ご興味のある方は、ぜひこの機会にお試しください。
予め計算されたソリューションライブラリは、引き続き従来のナッシュ均衡アルゴリズムを使用します。
なぜQREはポーカー戦略の自然な進化と言えるのか
QREの背景にある動機を説明するには、まず従来のナッシュ均衡戦略が抱える大きな課題の1つ、ゴーストラインを指摘しないわけにはいきません。
従来のソルバーは、完璧なプレイの下で起こり得るスポットのみを最適化し、「起こるべきでない」スポットについては切り捨ててしまいます。こういった0%頻度のスポットをゴーストラインと呼ぶこととしましょう。 ソルバーがあるノードやアクションを考慮する必要がないと判断すると、そのスポットの改良を打ち切り、対戦相手がゴーストラインに踏み込まない程度の「十分に良い」応答で妥協してしまいます。
問題は、レンジというものがそもそも定義できないことです。特定のラインを一切取らない対戦相手にはレンジが存在しません。では、その存在しないレンジに対して最適な反応をどう取ればよいのでしょうか?「幽霊[ゴースト]」とどう戦えば良いのでしょうか?また、ゴーストラインとどう戦えばよいのでしょうか?

QREはどのようにこの問題を解決するか
ナッシュ均衡が完璧なプレイを想定するのに対し、QREはプレイヤーが時々ミスを犯すという現実的な前提を導入します。 一見、 小さなミスを許容するという点で以下の「摂動完全均衡」と似ていますが、大きな違いがあります。
- 摂動完全均衡(Trembling‑Hand Perfect Equilibrium):ミスはランダムに発生する
- 質的応答均衡(QRE):EV損失に応じて確率的にミスを起こす(後悔が大きいほどミスを起こしづらくなる)
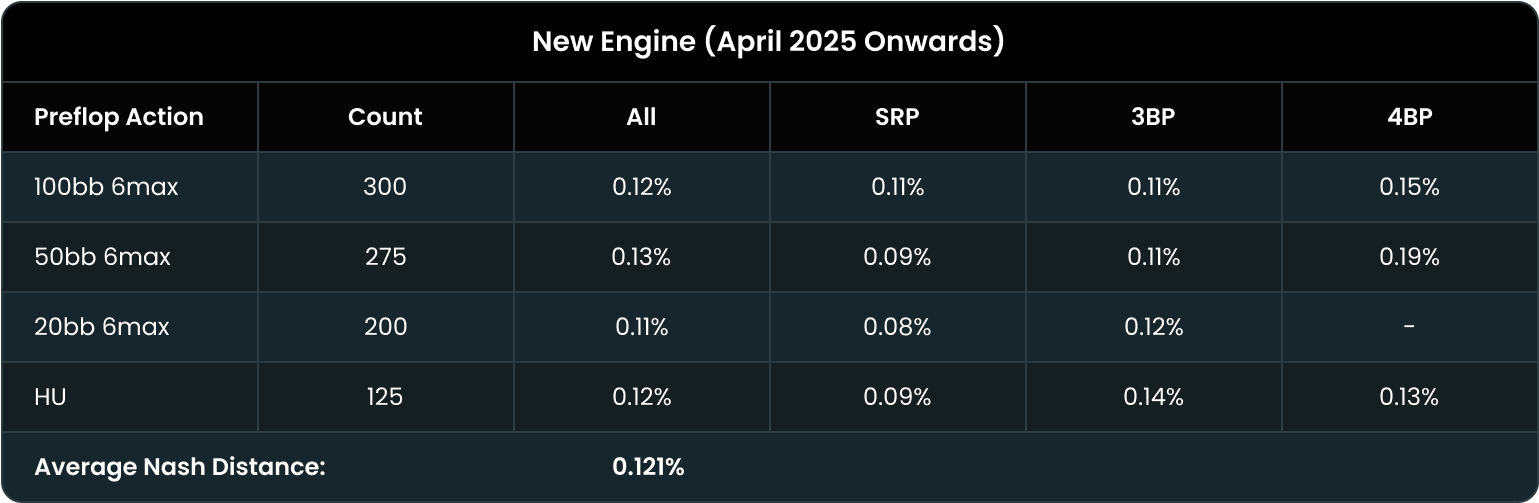
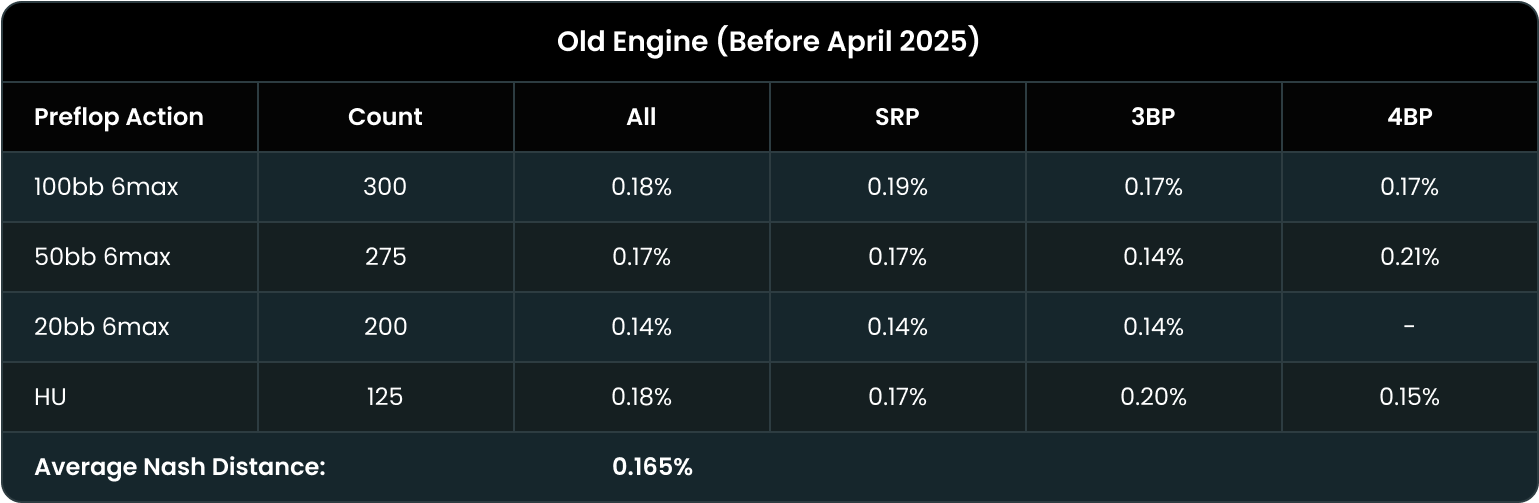
戦略に意図的なミスを組み込むことで精度が低下するのではと心配する方もいるかもしれません。しかし、これらのミスは極めて低頻度に設定されているため、戦略のexploitability(可搾取量)への影響はほとんど無視できる程度の影響しか及ぼしません。実際、最新エンジンは下記ベンチマークが示すとおり精度が25%向上しており、これまで同様、高品質なソリューションをご利用いただけますので、ご安心ください。
要するに、QREはノードロックを行うことなく相手のミスからより多くの利益を獲得できるということです。ゴーストラインに対しても最適な応答を返し、より頑強な戦略をもたらします。 このエンジンの改修は、今年予定している数多くの重要なアップデートへの布石となります。
完璧への道筋
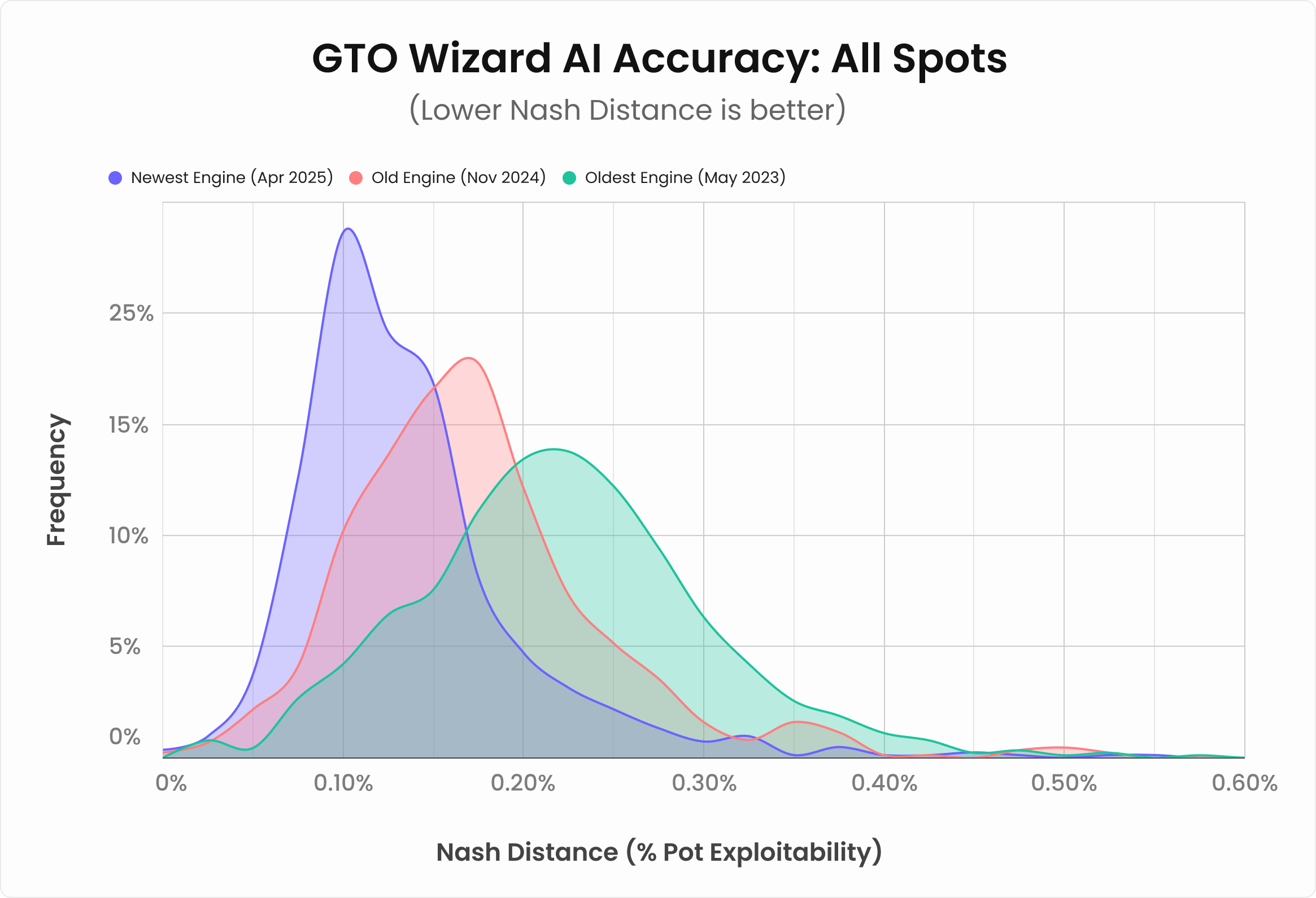
GTOは唯一無二の戦略のように語られがちですが、実際には絶対的な戦略ではありません。 常にわずかな誤差許容度、「ナッシュディスタンス」が存在します。例えば、GTO Wizard AIはポットサイズのおよそ0.1%までしか搾取できないようなナッシュディスタンスまで解を収束させています。その許容誤差の範囲内には複数の解が存在し複数の戦略がナッシュディスタンスの基準を満たしています。QREも従来のナッシュ均衡アルゴリズムも、このほぼエクスプロイト不可能なしきい値を満たしています。
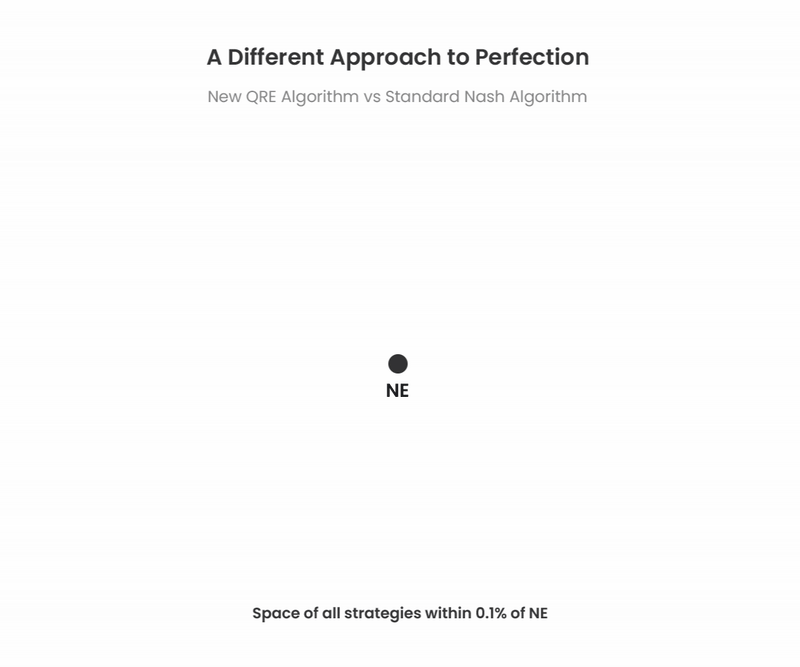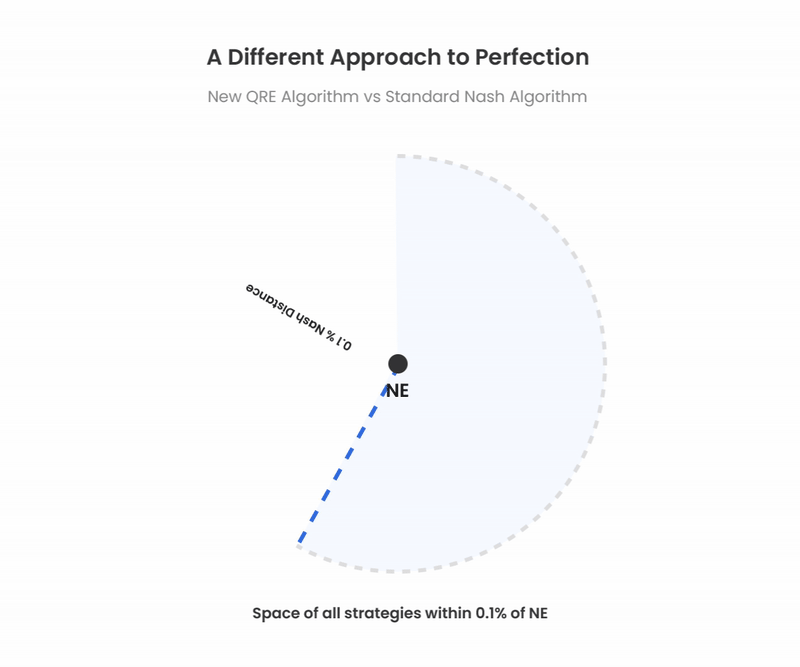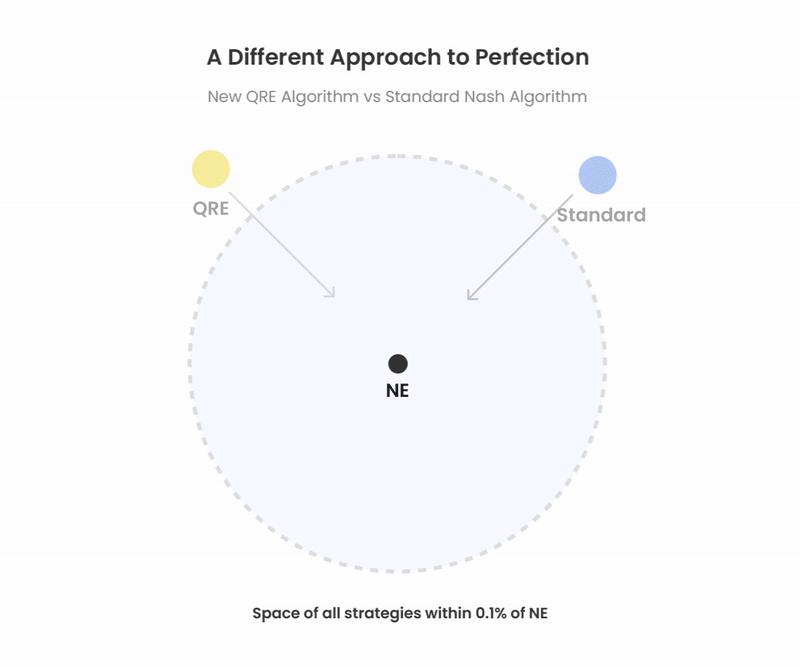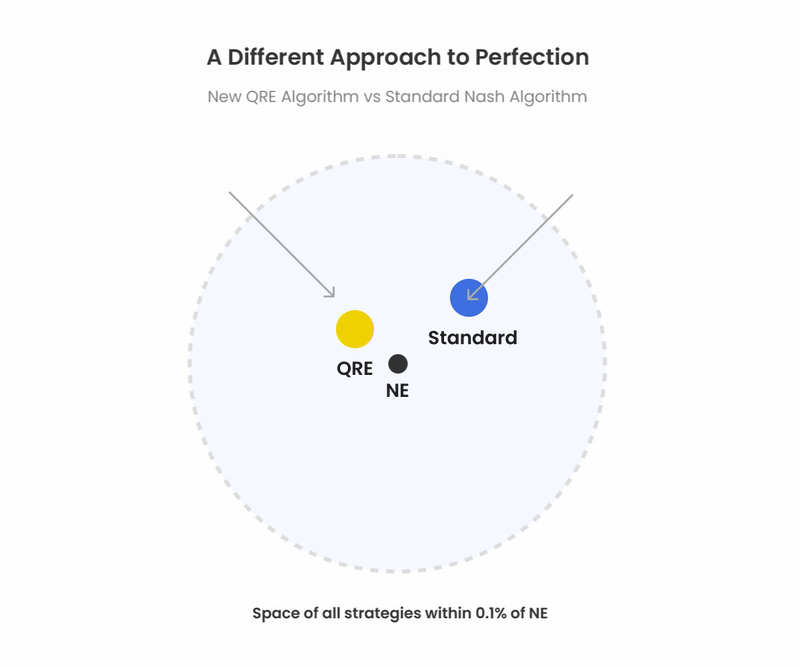
QREの実世界での応用
QREはポーカー戦略に留まらず、経済学や政治学、行動科学など幅広い分野で理論を革新してきました。 例えば、経済学者はオークションにおける過大入札の説明に、政治学者は選挙結果に影響をほとんど与えない当選確率の低い候補への投票を分析するのに、さらには高額賞金ゲームショー『The Price Is Right』に見られる非合理的な偏りの説明にQREを活用しています。現実の人間の行動をモデル化できるため、QREはポーカーの枠組みを超えて、様々な分野での意思決定において重要なツールとなっています。
戦略比較: QRE vs ナッシュ均衡
例1: ヘッズアップにおけるオープンオールイン
状況: HU、50bb、レーキなし、アンティなし。通常、SBはリンプか小さめのレイズを選択しますが、ここではSBが突然オープンオールインするケースを想定します。このときBBはどのように対応すべきでしょうか?
ナッシュ均衡: 計算結果には不自然な混合戦略が見られます。例えば、KQsを一部フォールドし、QTsを一部コールするといった矛盾した動きです。このようなオープンオールインに対して混合戦略にする必要はないですが、ソルバーは「オープンオールインはそもそも悪手」と判断した時点で最適応答の計算を打ち切ったため、戦略が収束していません。
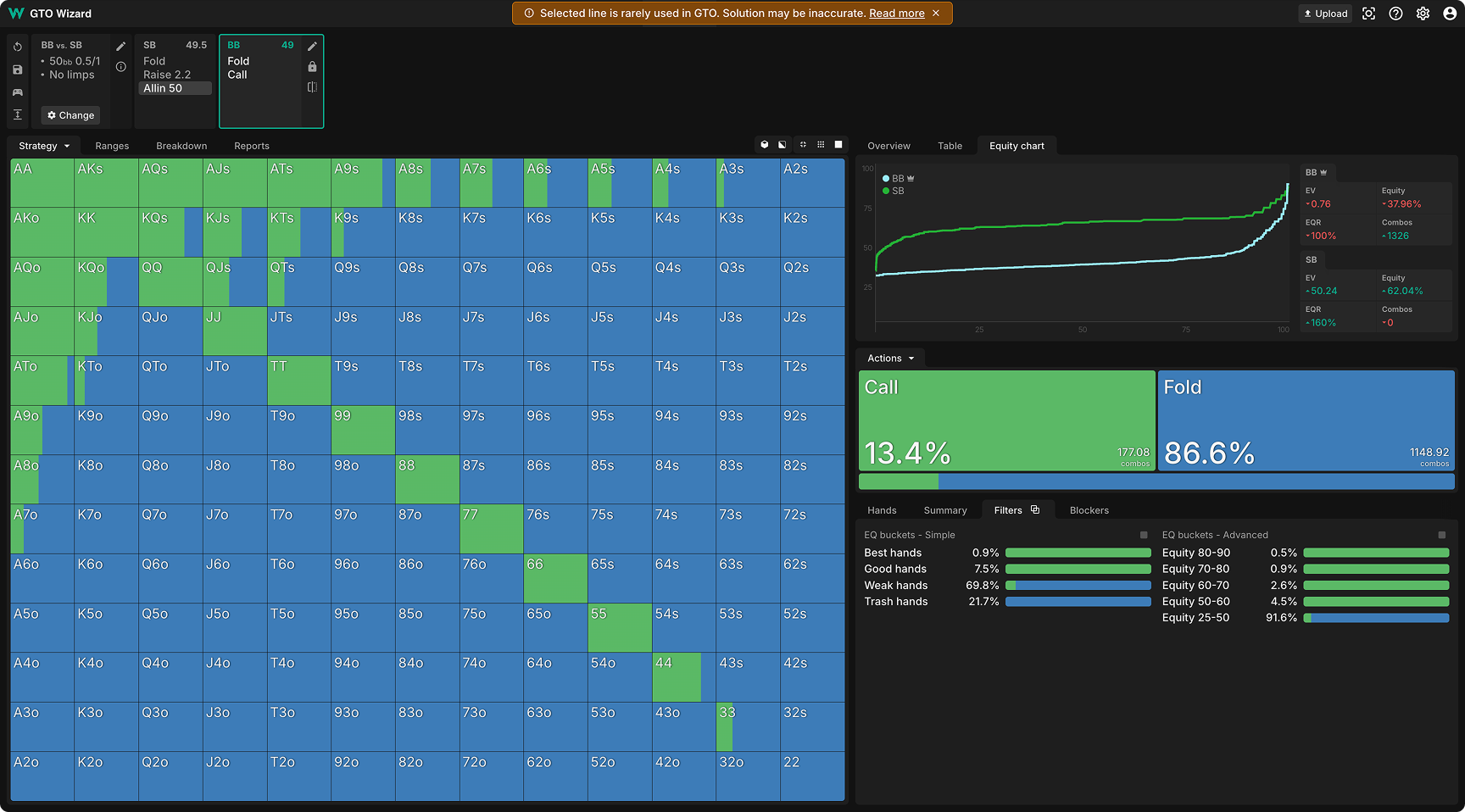
これまで、ゴーストラインでは上記の画像のように「Selected line is rarely used in GTO, solution may be inaccurate.(選択されたラインはGTOではほとんど使用されないため、ソリューションが不正確な可能性があります。)」と表示されていました。QREではこれをどう処理しているか見てみましょう。
QRE: このように、しっかり収束した純粋戦略になっています。ソルバーはヘッズアップでのエクイティが高いハンドをシンプルにコールし、コールレンジの全てのハンドが+EVを得られます。
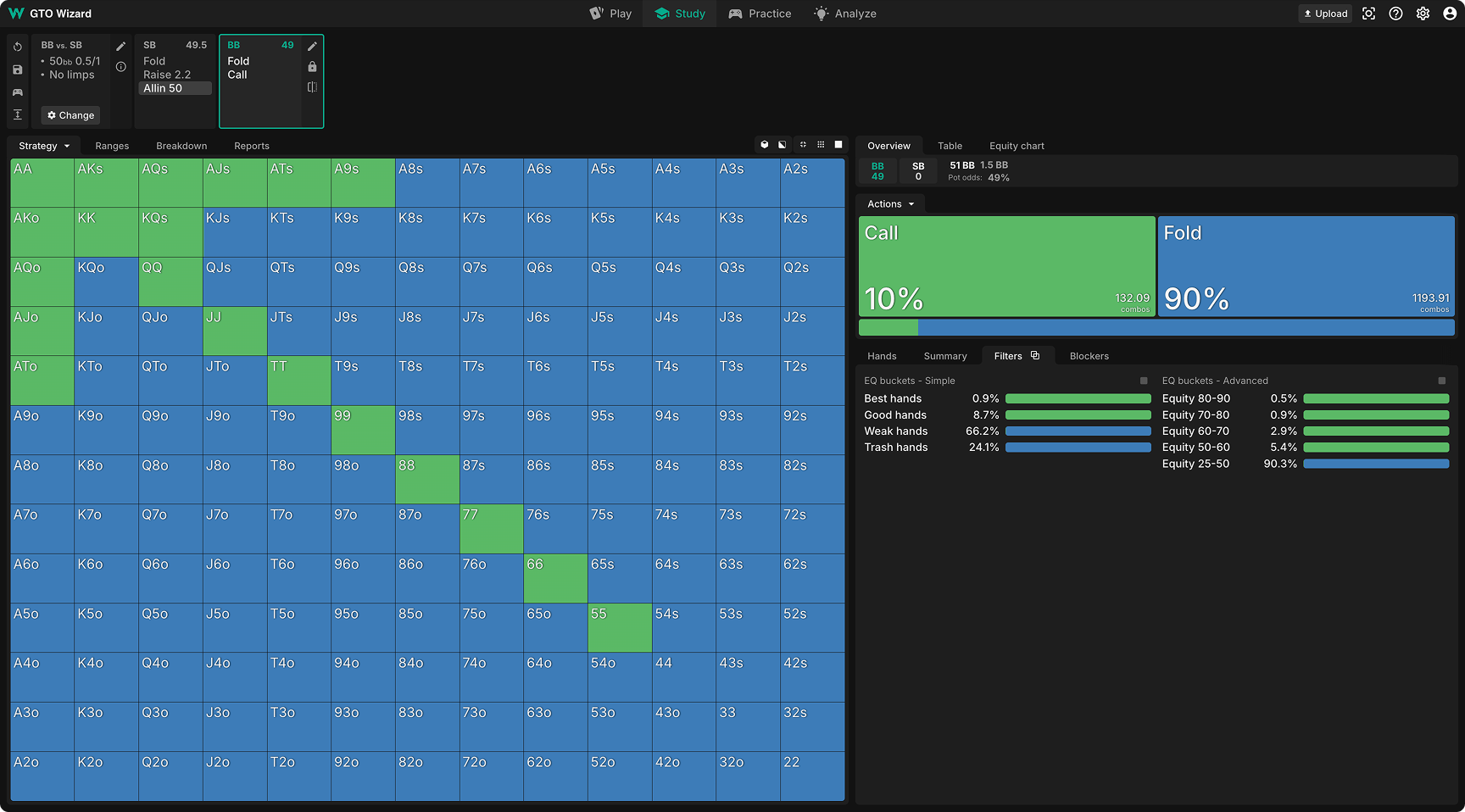
次にSB側のオープンオールインレンジを見てみましょう。QREが示すSBのレンジ(最頻ハンドを100%として大きさを調整しています)は、 ローポケや強いAx、そしていくつかの弱いハンドがランダムに混ざっており、初心者が犯しがちなミスを反映しています。
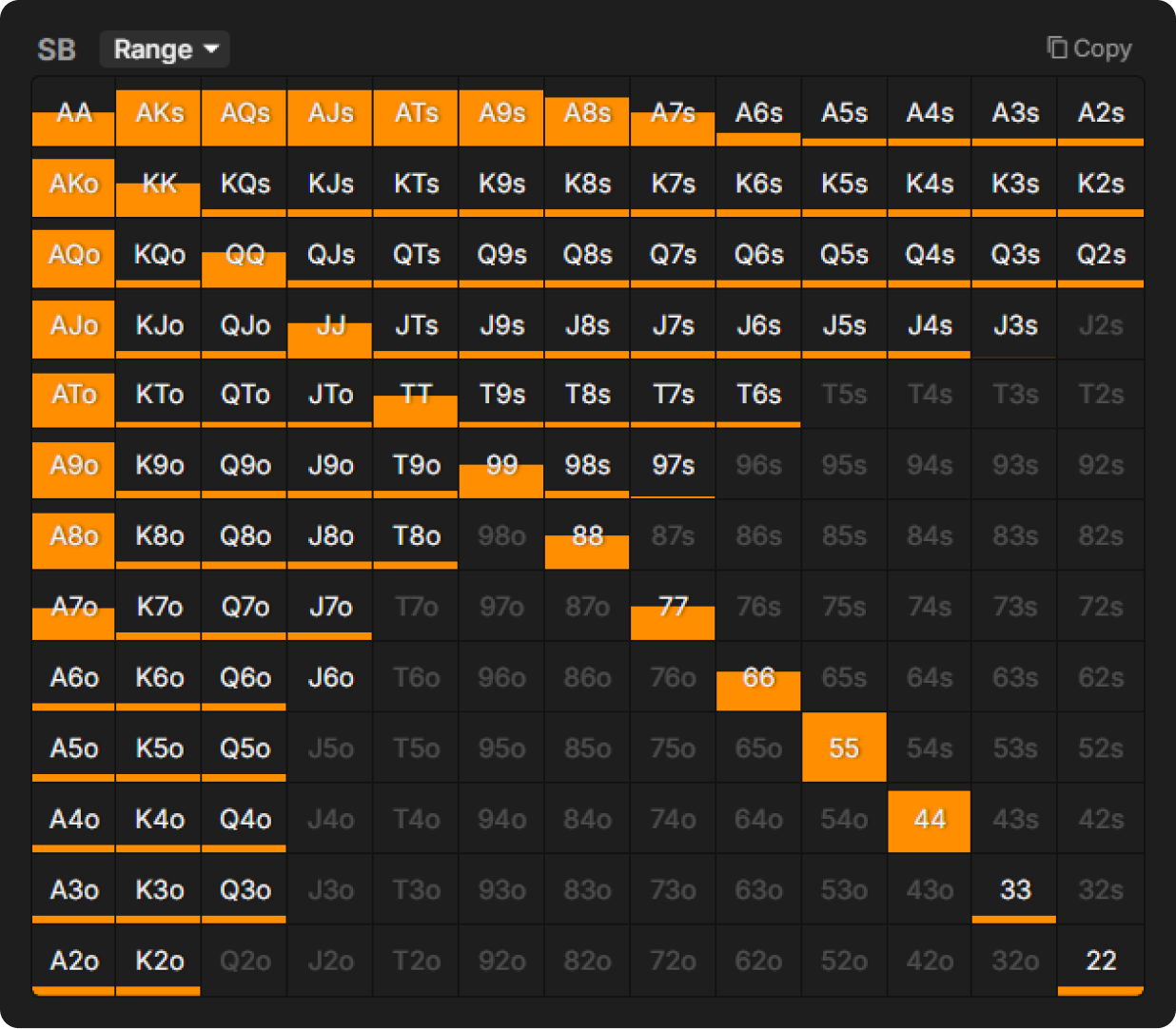
一方、ナッシュ均衡ではSBにオープンオールインレンジ自体が存在しないため、BBは相手のレンジを想定できず、反応も最適化されません。
例2: フロップドンクへの対応 – MTT
状況: 35bb、BTN vs BB SRP、MTTでは、AK6ボードはアグレッサーに非常に有利なスポットのため、本来BBはレンジチェックをすべきですが、ポットサイズのドンクベットをしたとします。このときBTNはどのように対応すべきでしょうか?
ナッシュ均衡: ほとんどのハンドでフォールドとコールの混合となっており、例えばセカンドペアをたまにフォールドし、8ハイでたまにコールするといった理解し難い動きが見られます。 さらにレイズレンジもバリューヘビーのオールインとキャップされたミニレイズが混ざったバランスの取れていない戦略になっています。このソリューションでは、ドンクノードが初期段階で切り捨てられたため、収束しておらず、反応は最適化されていません。
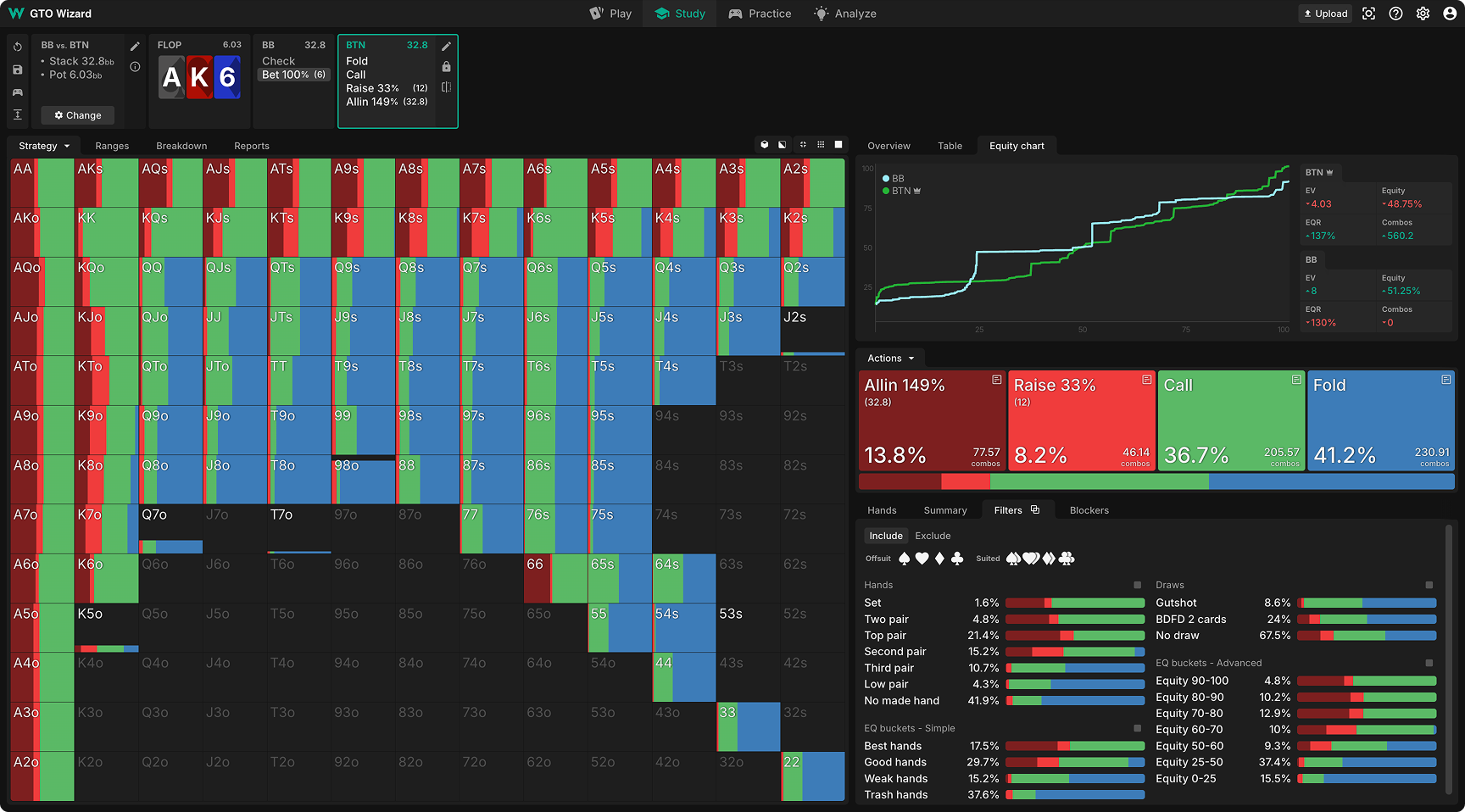
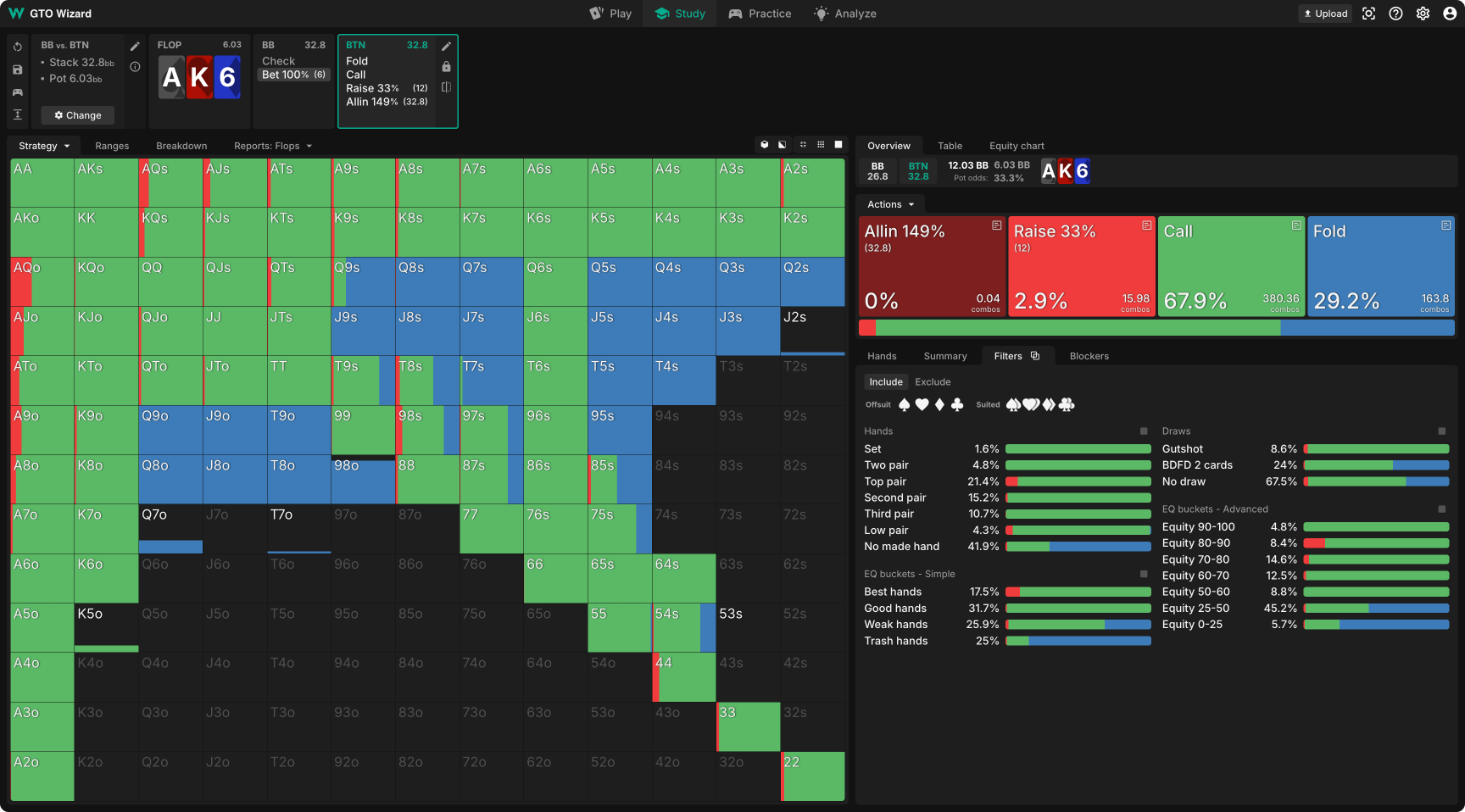
論理的かつ明快に収束した戦略が得られます。
QREのベンチマーク
一部のプレイヤーは、「意図的に戦略にミスを加えている」と聞いて不安に感じるかもしれません。ですが、実際には戦略の「合理性」を細かく調整していて、理論上ほぼ完璧に近い状態に仕上げています。
QREは相手のミスへの対応力だけでなく、実際に全体的な性能も向上しています。過去数か月でニューラルネットワークを改良し、AIソリューションのexploitabilityを大幅に低減しました。 フロップのソリューションのexploitabilityは平均でポットの0.165%から0.12%へと約25%減少しています。
つまり、最新エンジンは平均で25%高い精度のソリューションを出力します。QREはゴーストラインでのパフォーマンスが大幅に向上しているだけでなく、全体的にも優れています。
リバーの解析時間
アルゴリズム性能を測るもう一つの指標が収束速度です。リバーではポットサイズの0.1%まで解析を行います(つまり、そのリバーでの戦略は開始時のポットの最大0.1%までしかエクスプロイトされません)。
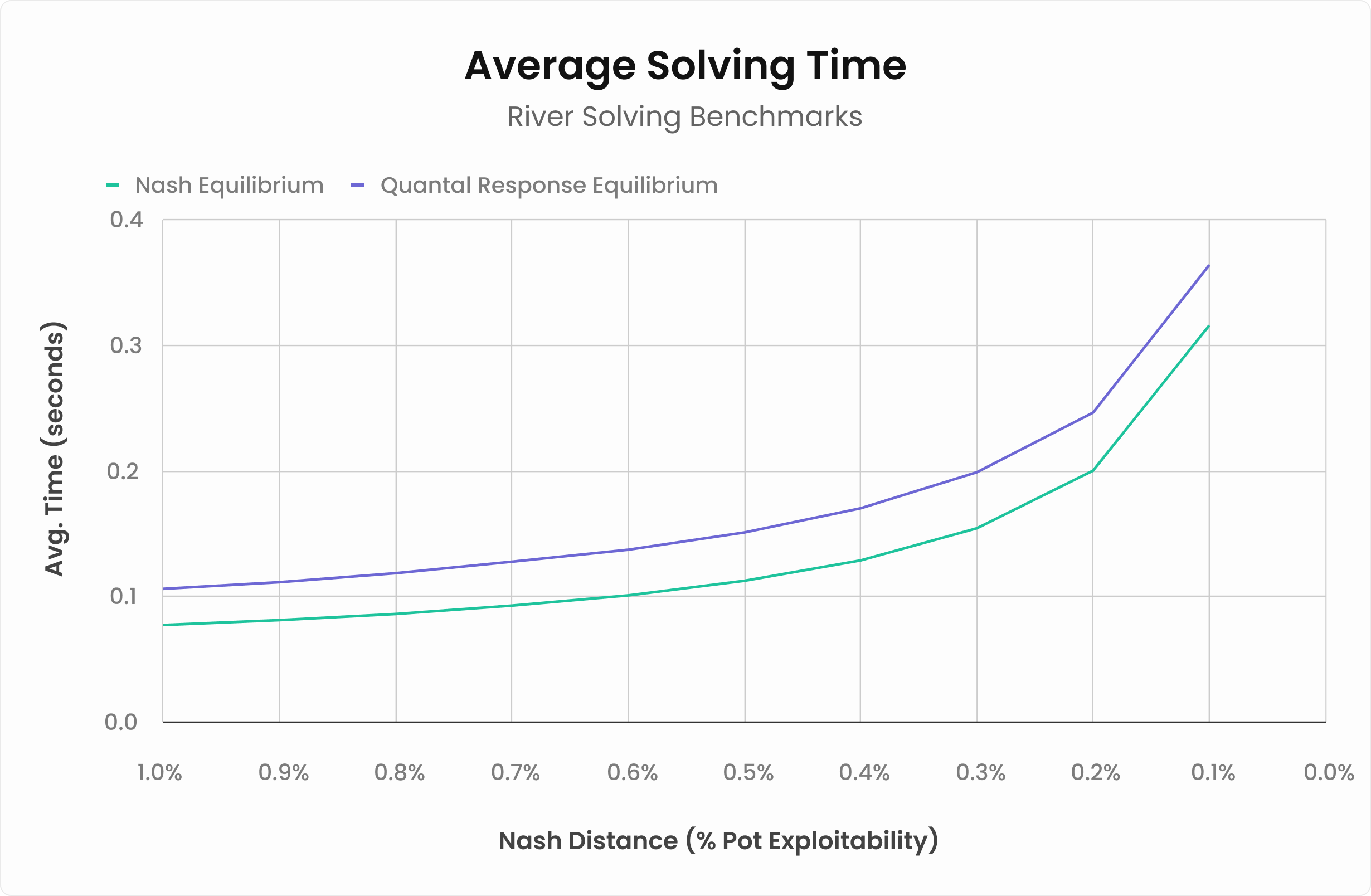
従来のナッシュ均衡アルゴリズムの方がわずかに速く(0.32秒 vs 0.36秒)、40msの差がありますが、この違いは体感できるほどではありません。一方、QREは非常に大きなスポットになると明らかに速くなります(7秒 vs 18秒)。解析に時間がかかる場面ではQREの方がスピーディーと言えます。
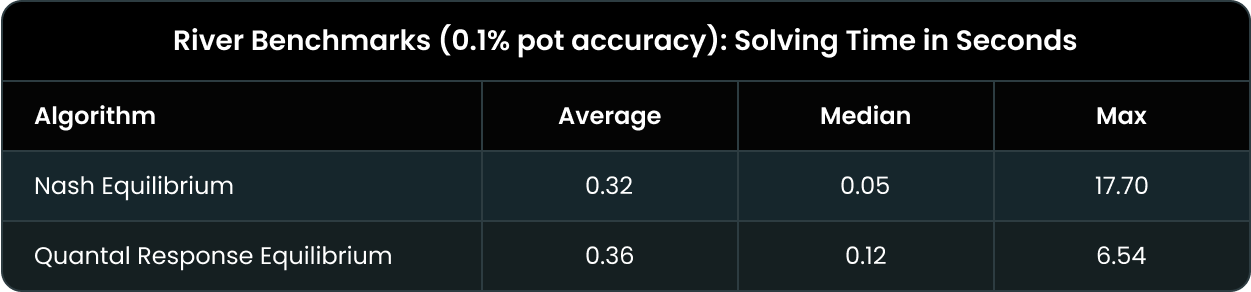
以下の図は、各アルゴリズムが一定のexploitabilityに到達するまでの時間を示しています。
ご覧のとおり、QREはナッシュ均衡と同等のexploitability到達までに要する追加時間はごくわずかです。
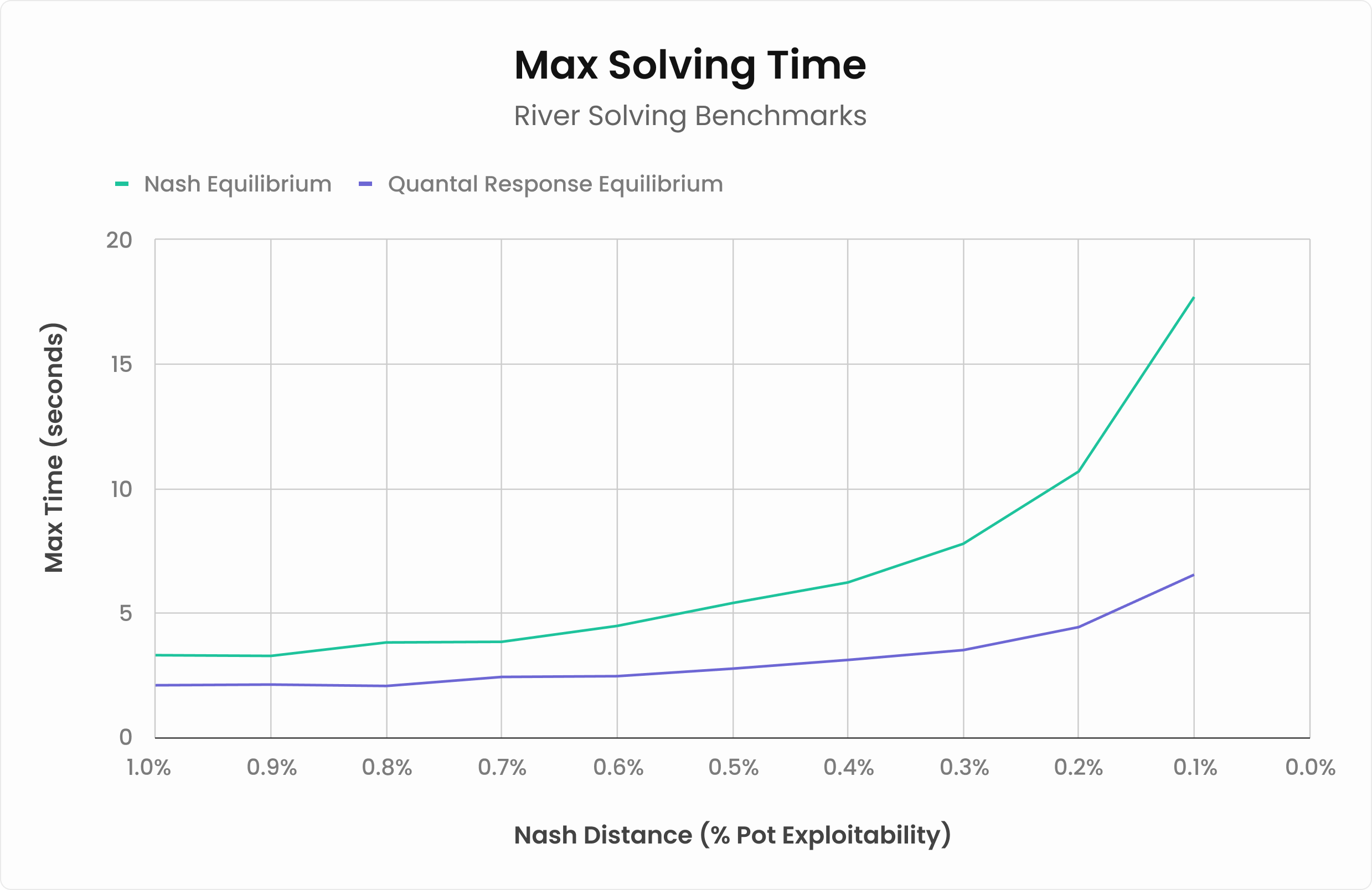
しかし、局面が大きく複雑になるほど、QREはナッシュ均衡よりもはるかに速く収束します。
ゴーストラインでの性能測定: Tree Payoff Weighted Loss
従来のexploitability、別名ナッシュディスタンスでは、QREが得意とするゴーストラインへの対応力を評価できません。
ナッシュで「発生しない」とされるスポットは戦略の精度に影響を及ぼさないため、exploitabilityでは測定不能だからです。しかし、実際にはプレイヤーはミスを犯し、ゴーストラインは発生し、その対応力こそがウィンレートを左右します。したがって、こうした低頻度ラインを考慮できる評価指標が欠かせません。そこで私たちは、この課題を解決する新しい指標、Tree Payoff Weighted Loss(TPWL)を考案しました。
TPWLはゲームツリー内の全てのノードを同等に扱い、ポットサイズや出現頻度に関係なく戦略の質を測定します。あくまで評価手法であり、実際のプレイ頻度を前提とするものではありません。
TPWL(Tree Payoff Weighted Loss)を計算するには、まず以下の用語を定義します。
- Best Decision
- Payoff Weighted Loss(PWL)
- Node Payoff Weighted Loss(NPWL)
Best Decisionとは、ゲームツリー内で他の全ての意思決定を固定したうえで、ハンドのEVを最大化するアクションを指します。複数のアクションが同一のEVをもつ場合、それら全て(またはその混合)をBest Decisionとみなします。
例: HU、IPのリバーで、自分がセカンドナッツを持ち、相手はベットに対しナッツのみをコールすると仮定します。この場合、Best Decisionは「チェック」です。これはナッシュ均衡とは無関係に、相手の戦略に基づいて決定されます。
Payoff Weighted Loss(PWL)は、あるハンドにおけるBest Decision EVから、実際にそのハンドで選択された戦略のEVを差を、ポットを獲得したときの価値(ポットサイズ)で割ったものです。つまり、特定のアクションの「後悔」をポットで割った指標と言えます。
例: レーキなしのキャッシュゲームでポットが200とします。あるハンドのチェックEVが50、ポットベットEVが100で、プレイヤーはそのハンドで90%ベット、10%チェックしているとすると、
- Best Decision EV = 100
- 実際の戦略のEV = 50 * 10% + 100 * 90% = 95
- PWL = (100 – 95) / 200 = 0.025
Node Payoff Weighted Loss(NPWL)は、特定のノードにおける全てのハンドのPWLの平均値です。
そしてTree Payoff Weighted Loss(TPWL)とは、ゲームツリー内の全てのノードにおける NPWLの平均値を指します。
TPWLには以下の3つの大きなメリットがあります。
- 均等重み付け: 全ての意思決定を等しい重みで扱い、低頻度スポットでのミスを可視化します。
- ポット正規化: ポットサイズを調整して評価するため、小さいポットでのミスが大きなポットでの良いプレイによって隠すことができません。
- 局所性: 任意のノードのNPWLは、そのノードを修正することによってのみ0にできます。つまり他のノードの好結果に埋もれません。
要するに、TPWLは従来の指標が見落としがちな稀だが搾取可能なラインを含め、戦略の総合力を評価する手法です。
TPWL指標による評価では、QREはナッシュ均衡を大幅に凌駕する性能を示しています。
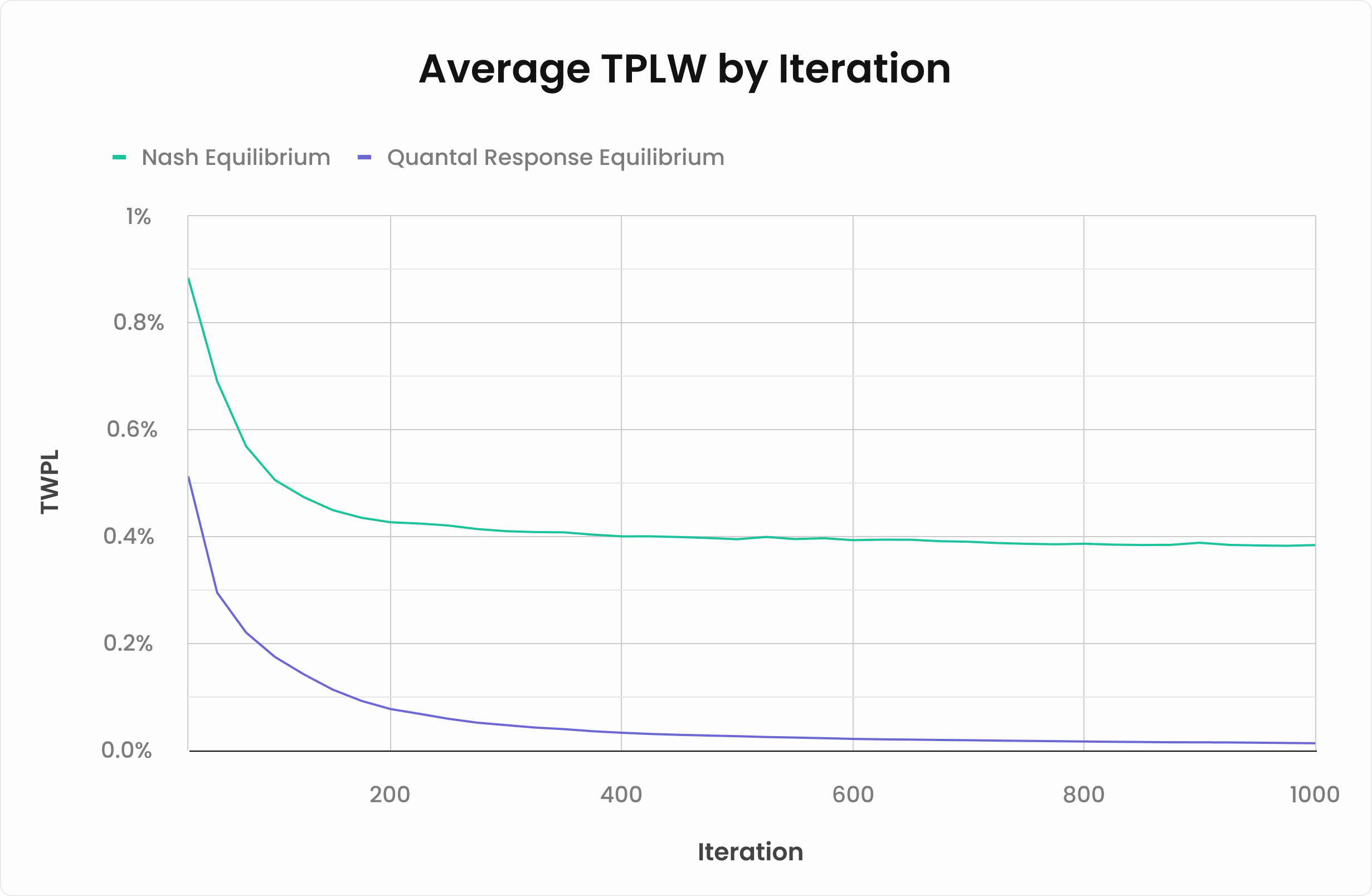
ここではリバーでのTPWLを計算し、従来のNEソルバーとQREソルバーを比較しています。NEソルバーは約0.38%で頭打ちになる一方、QREソルバーは素早く0.01%まで収束します。これは実に38倍のパフォーマンスの向上を意味します!
要するに、TPWLは「ツリー内の各ノードにおける戦略の質はどの程度か?」を測るのに優れた指標です。もちろん、exploitabilityは依然として最重要指標ですが、低い値を示すからといって全てのノードで良好なパフォーマンスが保証されるわけではありません。同程度のexploitabilityを持つ2つの戦略を比較した場合、TPWLが低い戦略ほど多様な状況で優れた結果を示します。TPWLが低い戦略はミスを犯す相手に対してより高いウィンレートを達成できることを意味します。
まとめ
QREは、ナッシュ戦略に続く次のステージとなる理論です。ナッシュが通常のラインを最適化する一方で、QREでは「起こるはずのない」スポットを含むあらゆる意思決定の最適化が可能です。端的に言えば、QREはミスを犯す完璧ではない相手に対してナッシュ以上のパフォーマンスを発揮します。
今回のソルバーの改良は、単に既存の戦略をパーフォーマンスを向上させるだけではありません。マルチウェイスポットや非ゼロサムといった、より複雑なシナリオを解くための重要な一歩です。
今後のさらなるアップデートにご期待ください!